
💡 ¿Quieres aprender más sobre diseño e inteligencia artificial? Mira mi nuevo Curso IA para Diseñadores. Inscripciones abiertas, cupos limitados.
Tres enfoques con AI para un mismo problema (y la importancia de ser pragmático).
Desde hace ya un tiempo, más allá de usar inteligencia artificial en lo cotidiano del trabajo, comencé a hacer diferentes experimentos integrando AI para resolver diferentes cosas. Soy de aprender haciendo y esta es una muy buena forma de probar las capacidades de la tecnología y desarrollar las propias. En este artículo justamente te cuento uno de esos experimentos, donde más allá de resolver el problema puntual, el propósito era probar.
Sin más, acá te cuento la experiencia.
Estoy seguro que más de alguna vez te has encontrado con más información de la que puedes leer y te inventas formas de conservar esas decenas de enlaces para leerlos en algún momento que nunca llega. Que te avergüenza la cantidad descontrolada de tabs en tu navegador que mantienes con la esperanza de leerlos “más tarde”. O que comienzas a agregarlos a aplicaciones tipo “read later”, guadarlos en bookmarks y otras formas que sólo hacen menos doloroso el asumir la pérdida que finalmente ocurrirá.
A mí también me pasa: suelo tener una cola interminable de artículos, newsletters, posts de blogs, LinkedIn y documentos que van quedando en la aplicación que utilizo para gestionar contenido. Cada día llega más y la pila sigue creciendo sin control. La paradoja es clara: el contenido, que debería ser una ayuda para pensar y aprender, se comienza a convertir en un problema.
El origen de estos contenidos no es arbitrario, son blogs, autores, newsletters, podcasts, todos contenidos que he elegido recibir y ahí hay una primera curatoría. Pero aún con ese filtrado, el volumen es importante.
En este punto, tengo que contar que la aplicación que uso para concentrar el contenido que recibo, es Readwise Reader y en otro artículo cuento más detalles del proceso de gestión de contenido que hago en Reader.
Desde hace algún tiempo comencé a aplicar un proceso de filtrado muy específico para identificar qué leer y cuándo y así intentar manejar esta cantidad enorme información. El primer paso es asumir que no podemos leer todo, y que la respuesta es gestionar mejor la información. Eso significa que hay que tomar básicamente 4 decisiones con el contenido:
- Qué es urgente y necesito leer ahora.
- Qué es importante, pero lo puedo leer más tarde.
- Qué es interesante y quiero conservar como referencia futura.
- Qué descarto y no voy a leer.
Los puntos 1 y 2 implican priorizar qué y cuándo voy a leer. El tercero se trata de asumir que no voy a leer en el corto plazo esos contenidos, pero veo valor en tenerlos accesibles. Finalmente, el 4 es reconocer que hay prioridades y que no podemos leer todo.
Esto es lo que se conoce como un triage: una evaluación rápida para clasificar la prioridad (de hecho, es el proceso que se aplica a los pacientes en los servicios médicos de urgencia).
Pero resulta que aún con un triage definido, el tiempo que demanda determinar qué leer y qué no, es significativo.
Es por eso que decidí aprovechar la oportunidad y usar esa dificultad como espacio de experimentación con AI.
¿Cómo aplicar diferentes enfoques con inteligencia artificial para resolver un problema tan práctico, como clasificar la cola de contenido?
Claramente el camino fue más largo del necesario si el objetivo sólo fuera simplificar el proceso: esto es más una excusa para probar diferentes enfoques con IA.
Lo que encontré en el camino es que se pueden probar integraciones avanzadas, automatizaciones complejas y diferentes arquitecturas, pero al final lo que realmente importa es ser pragmático: quedarse con la solución que funciona de la forma más simple y consistente.
Con esto último ya te podrás dar cuenta que el objetivo real es ganar experiencia de primera mano en procesos que muchas veces quedan a cargo de desarrolladores, pero que —estoy convencido— es imprescindible conocer para poder ponderar correctamente cómo aplicamos AI en las soluciones que diseñamos.
Qué partes del problema mejorar con AI
Para optimizar el proceso de triage de contenido, la primera pregunta es: ¿qué capacidades de la AI son más útiles para este contexto? Resulta que los modelos LLM son muy buenos para:
- Análisis de contenido, como tomar un artículo y resumirlo.
- Aplicación de reglas o heurísticas, como utilizar un conjunto de criterios para decidir.
- Razonamiento, como justificar las decisiones con fundamentos precisos.
- Clasificación, como por ejemplo, aplicar categorías temásticas.
Por lo mismo, no basta con que la AI lea el artículo, hay que enseñarle qué busco obtener y cómo quiero organizarlo.
Entonces, a partir de eso, la segunda pregunta es ¿dónde puede aportar más la AI para resolver mi problema? Hay dos momentos clave:
- Preprocesar contenido (antes de leerlo yo) y sugerir una acción del triage: leer primero, leer más tarde, archivar o eliminar.
- Clasificar temáticamente el contenido relevante para hacer más fácil encontrarlo cuando lo necesite.
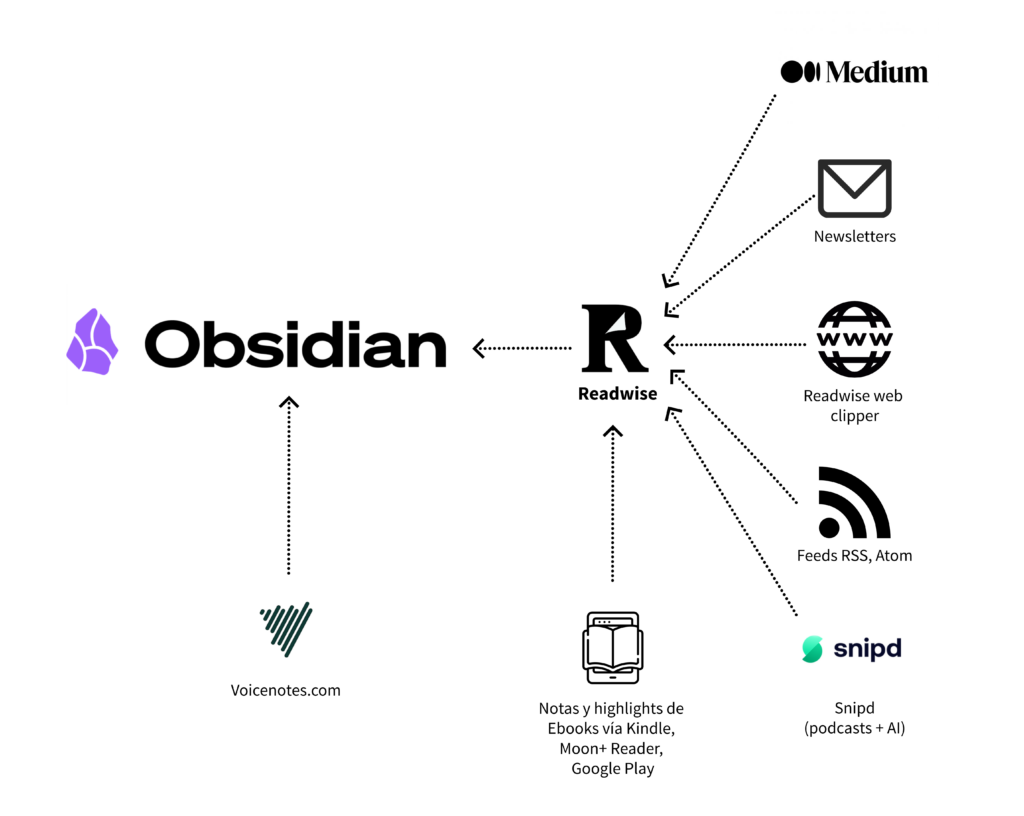
Pero para pasar el contenido de Reader a un LLM y hacer lo que espero, es necesario traerlo sin pasar por la interfaz web, conectarse directamente a la API de Reader. Esto permite obtener un listado de los contenidos nuevos en inbox, que es básicamente lo que necesito. El resultado viene en JSON que es un formato fácilmente consumible por cualquier AI.
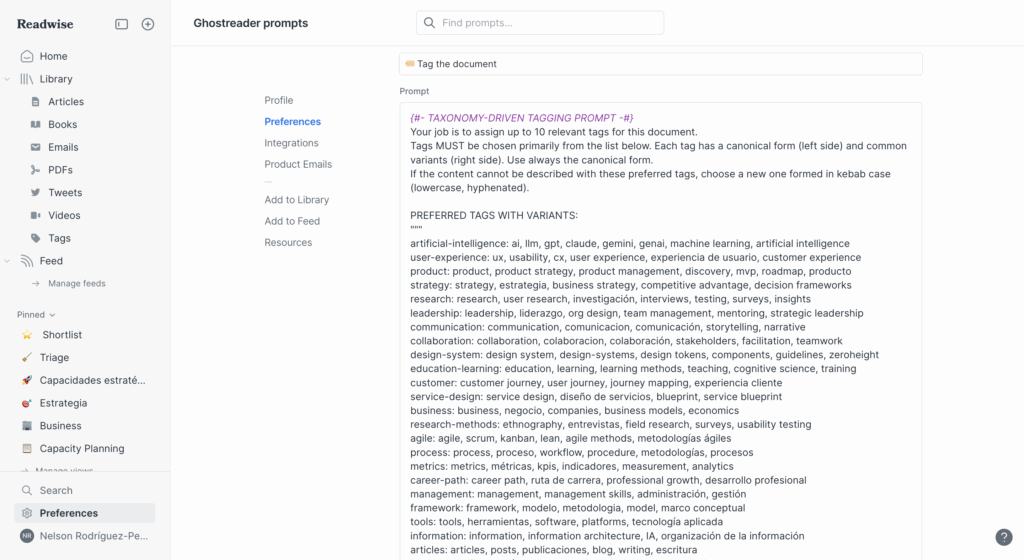
Adicionalmente, apliqué un paso previo con ChatGPT: tomé los casi 2.000 tags que he ido creando en Reader y una cantidad similar en Obsidian para mis notas. Esos tags, con su frecuencia de uso, representan claramente mi interés por diferentes temas, por lo que generar una lista con frecuencia es el primer paso para poder indicarle a un LLM dónde están mis prioridades y enseñarle cómo clasificar.
Junto con los tags, tengo reglas personales para generar tags, que deben ser consistentes y predecibles. En resumen, utilizo kebab case para las etiquetas, es decir, texto en bajas y palabras unidas por un guión.
También extraje una lista corta con autores que normalmente leo con interés (Peter Merholz, Teresa Torres, Roger Martin, etc.) y un subconjunto de los temas que estoy siguiendo con más interés en este período (artificial-intelligence, user-experience, product, career-ladder, strategy, etc.), y que me permiten indicar más explícitamente el foco de hoy.
Con todo esto, ChatGPT me ayudó a definir unas heurísticas que poder usar para informar a un LLM cómo realizar el triage y cómo clasificar.
La que sigue es una versión temprana, de ejemplo, de cómo me ayudó a definir reglas con precisión:
# --- Perfiles y prioridades ---
focus_topics:
- name: estrategia
keywords: ["strategy", "estrategia", "roger martin"]
weight: 3
valid_from: "2025-08-01"
valid_to: "2025-09-15"
- name: talento
keywords: ["talent", "talento", "people ops", "recursos humanos"]
weight: 3
- name: ai
keywords: ["ai", "artificial intelligence", "machine learning", "llm", "gpt"]
weight: 2
priority_authors:
- name: "peter merholz"
weight: 3
- name: "roger martin"
weight: 2
priority_sources:
- domain: "hbr.org"
weight: 3
- domain: "medium.com"
weight: 1
# --- Reglas de descarte ---
discard_rules:
blocked_sources: ["example.com", "clickbait.com"]
offtopic_keywords: ["viaje personal", "receta", "cumpleaños"]
duplicates_policy: "skip" # skip | allow
# --- Mapeo de tags ---
tagging:
- match: ["strategy", "estrategia"]
tag: "estrategia"
- match: ["talento", "people ops", "recursos humanos"]
tag: "talent"
- match: ["ai", "artificial intelligence", "llm"]
tag: "inteligencia-artificial"
- match: ["ux", "user experience"]
tag: "user-experience"Esto se ve muy técnico, pero son soluciones que uno va descubriendo en la práctica con un LLM mientras buscas. La clave es pedirle a ChatGPT (en mi caso) que sugiera estrategias para abordar un problema e ir dirigiendo el camino.
Con todo esto, ya nos podemos poner a jugar con diferentes enfoques.
Primer experimento: API de Reader + LLM
Mi primera prueba fue construir una app con dos componentes: un proceso en un servidor web que realizaba la conexión con Reader vía API y un LLM para clasificar y sugerir acciones para triage. Esto se gatilla con un cron job (una tarea programada) que lo ejecuta todas las mañanas.
Este primer ejercicio lo comencé en un servidor web, pero lo terminé implementando en un servidor local por rapidez y control.
Para la app usé React (con Vite y Tailwind) para facilitar un front rápido y sin demasiada complicación, que consumiera la API de Reader y se conectara con un modelo de inteligencia artificial de Gemini para sugerir tanto la acción de triage como los tags relevantes.
En este punto hay varias consideraciones:
- Yo no soy desarrollador, pero aprendí a programar hace muchos años y no me cuesta, aunque en React sólo he realizado pruebas, nada en productivo.
- La conexión Visual Studio Code + ChatGPT facilita mucho el desarrollo. Básicamente pido cosas concretas al modelo de AI y me aseguro de que esté haciendo lo correcto y no haya errores muy evidentes, que suele haber.
- Derivar tareas a un LLM tiene costos: cuando llamas un endpoint de un LLM como los de OpenAI, Gemini, etc., no es gratis, así que es importante considerar la eficiencia de los llamados, familiarizarte con qué modelo resuelve mejor qué y a qué costo, etc. En general, los precios son muy accesibles y además hay cuotas de uso para pruebas gratuitas.
Esta es la interfaz de lo que armé con este enfoque. La versión en front no quedó exactamente igual, pero sí suficientemente similar.
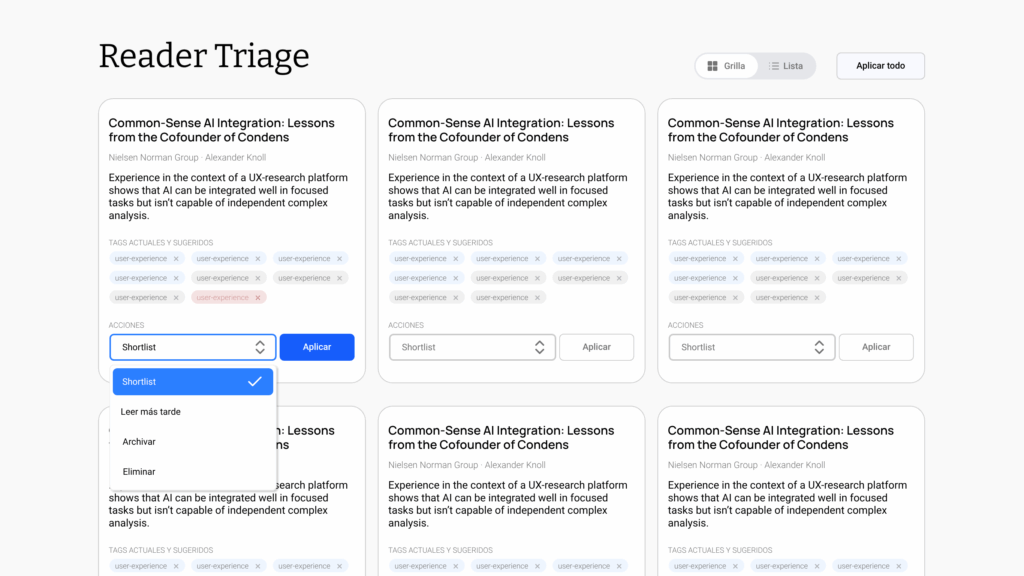
Lo que hace la app es:
- Traer contenido nuevo de Reader y listarlo.
- Sugerir una lista de tags para organizar temáticamente cada artículo.
- Sugerir la acción a tomar: marcar para lectura inmediata; leer después; archivar para referencia futura; eliminar.
Acá ya comienza a ser evidente lo fácil que es sobredimensionar una solución para un problema que, en esencia, pedía simplicidad.
También aparecen algunos conceptos que es bueno manejar: cuando estás enviando solicitudes al endpoint de un LLM, básicamente le envías un prompt. Este prompt está compuesto de dos partes:
- Un prompt de sistema, que es la estructura base de lo que le estás pidiendo, con un formato definido y un output determinado, por ejemplo, JSON, que resulta fácil de manipular posteriormente.
- Un prompt de usuario o la data específica que pasas para procesar. En este caso, un artículo.
Veamos algunos ejemplos:
Éste es el prompt para conseguir un resumen breve de un artículo. Está compuesto por la instrucción base (‘Write a single short paragraph…‘) y se le pasa como parámetro el artículo.
`Write a single short paragraph (1-2 sentences, <= 45 words) in neutral Spanish (LatAm) summarizing the following content:\n"""${article}"""`En este otro ejemplo, el prompt pide al LLM clasificar un artículo:
You classify articles thematically.
Choose up to 5 tags from ALLOWED_TAGS only (canonical names). Do not invent tags.
Map any found variant to its canonical; output canonical only.
If more than 5 are relevant, prioritize: 1) terms in title, 2) terms in headings, 3) frequency in body, 4) semantic centrality. Break ties preferring relevant items in existing_tags.
If none apply, return [].
Normalize for comparison: lowercase, trim spaces, remove diacritics.
Prefer items in existing_tags only if they are relevant.
Return ONLY compact JSON, one line, no markdown, no prose.
ALLOWED_TAGS (canonical → variants):
{aquí va un mapeo claro, ver versión robusta}
existing_tags:
{["tag1","tag2",...]}
This is the article to classify:
{pega aquí el artículo (texto plano)}(Los ejemplos están simplificados para eliminar código y dejar sólo lo más relevante)
Es común que lo que quieres obtener de resultado sea un formato estandarizado, que sea fácil de procesar. Las respuestas en formato “narrativo” (como en el primer ejemplo) requieren más tratamiento si no las vas a usar directamente. Por eso, se enfatiza en las instrucciones qué se espera de salida: Return ONLY compact JSON, one line, no markdown, no prose.
Elegí JSON como formato de salida porque me asegura consistencia y facilidad para procesar los resultados en cualquier flujo posterior.
Otro problema en el camino
Desde temprano aparece un problema práctico importante: la API de Reader no tiene la capacidad de escribir, sólo de leer. Es decir, puedo consumir contenido, traer un listado de los contenidos nuevos, pero no tengo métodos para cambiar un artículo de ubicación (de inbox a Read Later, por ejemplo), con lo que el ejercicio se complicó.
Una opción es usar alguna app como Playwright o Selenium, que permiten automatizar tareas en un navegador headless, realizando acciones tal como las haría una persona. Lo que hace este tipo de aplicaciones es:
- Grabar o mapear las acciones de una interfaz gráfica como lo usaría un humano con el teclado y el mouse.
- Definir escenarios de uso como “agregar tags” o “marcar como Read Later”.
- Aplicar las acciones automáticamente, sin la intervención de una persona.
En el caso de este experimento, por ejemplo, los tags y las sugerencias de acciones que define el LLM se le pasan como parámetro a Playwright y las ejecuta sin intervención humana. Es una forma de suplir la falta de acceso programático vía API a acciones de escritura o modificación en Reader.
Pero ya en este punto, la conclusión era clara: demasiada complejidad para un problema que pedía simplicidad. Vamos con otra alternativa.
Segundo intento: automatización con n8n
El siguiente paso fue probar con n8n, una herramienta para automatización de flujos. Acá el primer paso fue hacer una instalación local de n8n, que siendo un proyecto open source, ofrece la posibilidad de hacerlo, junto a la disponibilidad de planes pagos.
Armé un flujo que traía los contenidos de Reader, los dividía en unidades y los pasaba por un proceso de análisis.
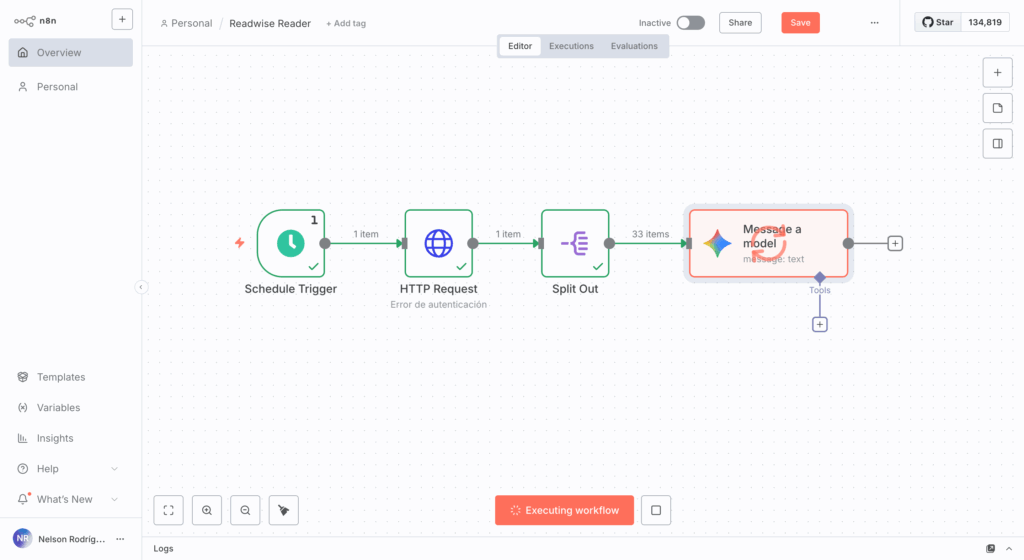
El flujo en la imagen muestra:
- El primer paso es la programación de la frecuencia, en este caso, diaria.
- El segundo paso es una conexión vía API con Reader para traer la colección de artículos nuevos.
- Como normalmente se trata de una lista de artículos, acá los divido para poder manipularlos individualmente.
- Finalmente se hace una conexión con un LLM, en este caso gemini-2.5-flash para pasarle los artículos y proceder a clasificar y definir acciones de triage.
En la siguiente imagen, se muestra uno de los pasos de configuración de la conexión con el LLM. A la izquierda vemos el input del paso anterior, la lista dividida de artículos; al centro parte de la instrucción para que Gemini procese el artículo y a la derecha el panel de ejecución de la solicitud.
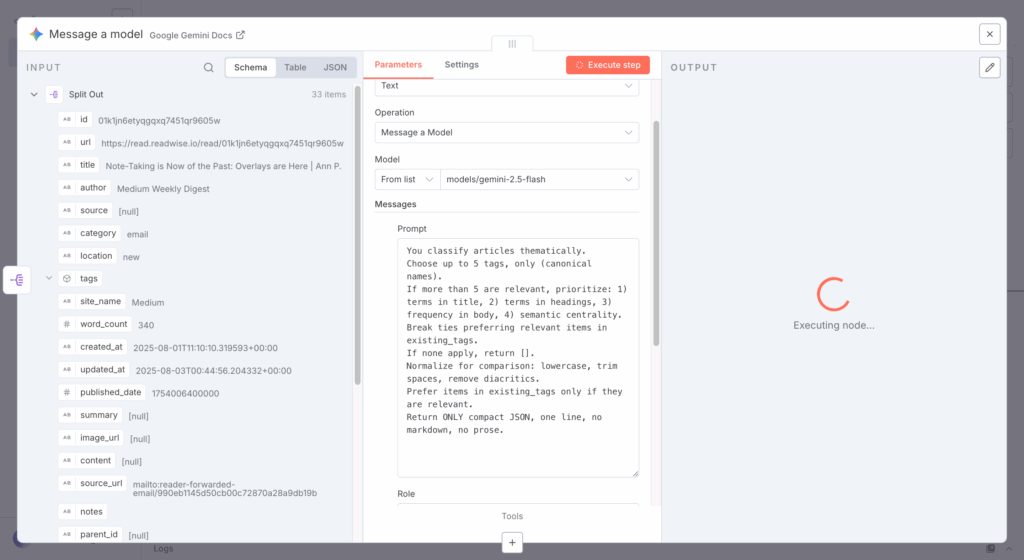
El problema volvió a ser el mismo: podía consumir la información, pero no ejecutar acciones dentro de Reader. Eso significaba que la automatización quedaba a medias y que el esfuerzo invertido no compensaba el beneficio real.
Aún así, el proceso es mucho más eficiente que el desarrollo directo de una app, por lo que si se trata de una automatización personal, como en este caso, es una mucho mejor alternativa.
n8n resultó ser un punto medio interesante: mucho más rápido de implementar que programar desde cero —incluso con ayuda de una AI—, pero aún insuficiente porque Reader no permite ejecutar acciones sobre el contenido.
La solución más práctica: prompts en Ghostreader
Después de haber probado soluciones viables, pero complejas, para este caso en particular la respuesta más efectiva termina siendo la más simple: Reader tiene una herramienta llamada Ghostreader, que es un conector con un LLM que permite hacer solicitudes específicas a una AI, vía prompt.
Se trata de una funcionalidad relativamente reciente, que conecta con un modelo de AI, le entrega una instrucción y recibe el resultado. Para mi triage, configuré dos prompts personalizados:
- Uno que sugiere la acción de triage (leer ahora, guardar, archivar o eliminar).
- Otro que sugiere los tags más relevantes, basándose en mi set curado.
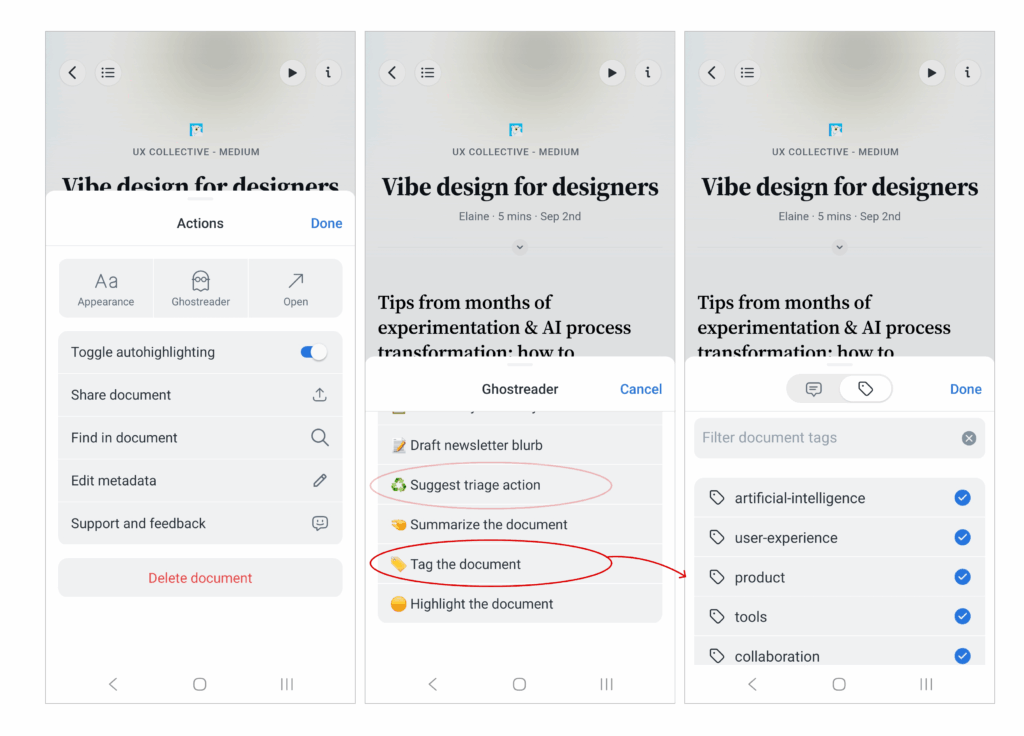
En las imágenes se puede observar la funcionalidad de Ghostreader en la app móvil (también lo puedo usar en desktop). Al tocarla, muestra todos los prompts que he creado y algunos propios de Reader, que también puedo editar. Finalmente, si pido etiquetar el artículo activo, me sugerirá un conjunto de tags muy acertado.
¿Es una solución ideal? No, porque requiere un par de pasos adicionales, pero definitivamente es más rápido que hacerlo manualmente. Hubiera sido lindo que mi diseño de una web app pudiera ejecutar acciones directamente, pero no es el caso por las limitaciones de la API.
Una conclusión personal
Como te contaba al inicio, esto fue un ejercicio más de aprendizaje y experimentación, antes que de buscar la solución más eficiente. Podría haber comenzado con Ghostreader y resolver rápidamente, pero el propósito era probar diferentes herramientas y estrategias.
Aún así, destaco que en un caso real, es el pragmatismo el que debe priorizarse, la solución más eficiente y de bajo mantenimiento es la más indicada la mayoría de las veces.
Y creo que ése es el dilema que muchos enfrentamos con AI: probar cosas complejas es valioso para aprender, pero cuando se trata de trabajar, lo que importa es lo que realmente simplifica y funciona.


